Changelog / Version history: Update (Nov 29, 2025)
These posts are early geometry probes (intuition/creativity/wisdom) written before the project switched to a more general string-theory operator toolkit for the same underlying operations (multi-scale flow, chart/gauge structure, and action/functional framing). The “ladder/zoom/jump” machinery here is preserved as a historical sketch; the current formalism lives in the Kernel / later docs.
Status: Concept proposal (unvalidated).
More materials (work-in-progress): https://osf.io/85z3u
TL;DR
We propose a method to teach AI something like intuition:
- Know when to zoom — use more representational detail only when it’s worth the cost.
- Know where to jump — predict a better direction that only appears at higher-dimensional detail.
The approach combines Cross-Dimensional Contrastive Learning (CDCL), Dimensional Distance Profiles (DDP), and a fold-aware jump policy that triggers proactive cross-scale moves when low-dimensional geometry hints there’s a better solution “across a fold.”
Note: This is a theoretical proposal; experiments are forthcoming.
Part 1 — A human-friendly explanation
Intuition, in one picture
You spot a friend across a plaza. First comes gist (cheap, fast). If unsure, you zoom (more detail). Sometimes a tiny cue makes you jump — you just know it’s them without scanning every face.
We propose training AI to do that:
- Zoom only when cheap signals suggest it will help.
- Jump early when low-dimensional patterns indicate the problem will “untangle” at higher dimension.
Why this might help
Embeddings can reshuffle neighbors when you change dimension (e.g., 256 → 1024). Systems either recompute a lot (slow/expensive) or risk missing long-tail matches. Stabilizing geometry across dimensions and adding fold-aware jumps could keep quality while avoiding brute force.
Part 2 — How it works (still friendly)
The ladder
Use a fixed dimensional “ladder,” e.g., 128 → 256 → 512 → 1024, with a versioned basis so geometry is comparable across steps (and auditable).
DDP: Dimensional Distance Profiles
For any pair (A, B), track distance vs. dimension. Positives should stay flat as you zoom; negatives should separate.
The zoom gate (policy)
From cheap, low-d signals — margin, stability-delta (how much rankings changed since last step), and residual headroom — estimate the expected value of zooming minus its cost (latency/compute). Zoom only if it’s worth it.
Controller (v1.5): we use a contextual bandit to pick stay/zoom from cheap signals and a compute-cost prior. A hysteresis deadband (τlo < τhi) prevents thrash. We run a lightweight pilot-zoom on ~5–10% of the shortlist to estimate the expected gain before full escalation. With conformal abstention, the system can say “I don’t know” (or escalate) when non-conformity exceeds a threshold 
The fold-aware jump (proactive)
Sometimes the low-d view suggests a topological fold: rapid neighbor swaps, DDP curvature, or “meet-again” behavior. When those cues appear, predict a small residual direction in the higher-d space and jump before local search fails.
Part 3 — Show me the math (for practitioners & reviewers)
Notation
- Encoder:
outputs
. We use the unit-norm version
.
- Fixed orthonormal basis:
(columns are orthonormal).
- Prefix / residual at depth
:
,
. If
then
.
- Optional normalized $d$-view:
(use for contrastive losses only).
- Residual headroom:
.
- Cosine (certificate space) at depth
,
.
- Production distance (score) — ARD-RBF: with
,
,
, define
.
- DDP (Dimensional Distance Profile): the curve
under the chosen metric.
- Positives/negatives for a query
:
/
.
- Depth ladder:
denotes the served dimensions (e.g.,
).
Early-stop certificate (cosine domain)
By Cauchy–Schwarz on residuals, the full-D cosine lies in
![\boxed{\ \cos_D(x,y)\in\big[\ \cos_d(x,y)\mp \sqrt{\epsilon_d(x)\,\epsilon_d(y)}\ \big]\ }](https://s0.wp.com/latex.php?latex=%5Cboxed%7B%5C+%5Ccos_D%28x%2Cy%29%5Cin%5Cbig%5B%5C+%5Ccos_d%28x%2Cy%29%5Cmp+%5Csqrt%7B%5Cepsilon_d%28x%29%5C%2C%5Cepsilon_d%28y%29%7D%5C+%5Cbig%5D%5C+%7D&bg=ffffff&fg=000&s=0&c=20201002)
Certification rule: at depth 


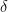
Training: CDCL + DDP shaping
Goal: learn geometry that is (i) contrastive at each depth and (ii) stable/smooth across depths so low-d works fast and high-d refines.


Definitions used below: ![\delta_{+}^{(d)}(x)=\mathrm{E}_{y\in\mathcal{P}(x)}[\delta^{(d)}(x,y)]](https://s0.wp.com/latex.php?latex=%5Cdelta_%7B%2B%7D%5E%7B%28d%29%7D%28x%29%3D%5Cmathrm%7BE%7D_%7By%5Cin%5Cmathcal%7BP%7D%28x%29%7D%5B%5Cdelta%5E%7B%28d%29%7D%28x%2Cy%29%5D&bg=ffffff&fg=000&s=0&c=20201002)
![\delta_{-}^{(d)}(x)=\mathrm{E}_{y\in\mathcal{N}(x)}[\delta^{(d)}(x,y)]](https://s0.wp.com/latex.php?latex=%5Cdelta_%7B-%7D%5E%7B%28d%29%7D%28x%29%3D%5Cmathrm%7BE%7D_%7By%5Cin%5Cmathcal%7BN%7D%28x%29%7D%5B%5Cdelta%5E%7B%28d%29%7D%28x%2Cy%29%5D&bg=ffffff&fg=000&s=0&c=20201002)


Total loss:

Notes: 

![\mathrm{E}[\cdot]](https://s0.wp.com/latex.php?latex=%5Cmathrm%7BE%7D%5B%5Ccdot%5D&bg=ffffff&fg=000&s=0&c=20201002)
Zoom policy (Expected Value of Computation)
Idea: start cheap (low-d). If quick cues predict a gain from “zooming,” pay the cost to go deeper.

Cost model: 
Here 

 and a compute prior. We apply hysteresis with thresholds τlo < τhi to avoid reversals, run a pilot-zoom on ~5–10% of the shortlist to estimate
and a compute prior. We apply hysteresis with thresholds τlo < τhi to avoid reversals, run a pilot-zoom on ~5–10% of the shortlist to estimate  , and use conformal abstention (threshold ) to abstain or escalate when uncertain.
, and use conformal abstention (threshold ) to abstain or escalate when uncertain.
Cross-scale lift (jump)
When low-d looks “braided,” predict a residual direction in the higher-d subspace and leap there.


![\tilde z=\mathrm{Norm}\big([\tilde z^{(d^*)};\,\hat r]\big)](https://s0.wp.com/latex.php?latex=%5Ctilde+z%3D%5Cmathrm%7BNorm%7D%5Cbig%28%5B%5Ctilde+z%5E%7B%28d%5E%2A%29%7D%3B%5C%2C%5Chat+r%5D%5Cbig%29&bg=ffffff&fg=000&s=0&c=20201002)

Where: 

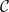


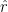
Fold-aware proactive trigger
- DDP curvature:
(second difference of mean distance).
- Neighbor-swap rate (braiding):
(Kendall
between neighbor orders across depths).
- Meet-again / reconvergence score (diverge then agree again in higher-d).
- Residual headroom:
- Hubness skew around the query (unstable hubs → likely fold).
Definitions: 
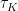

Fold potential head:

Decision energy:
![\Delta U_{\mathrm{jump}}(d\!\to\!d')=\mathrm{E}\big[\mathrm{Gain}_{d'}-\mathrm{Gain}_{d}\mid x,\,\boldsymbol{\phi}_{d}\big]-c_t\,\Delta t(d,d')-c_c\,\mathrm{Cost}(d')](https://s0.wp.com/latex.php?latex=%5CDelta+U_%7B%5Cmathrm%7Bjump%7D%7D%28d%5C%21%5Cto%5C%21d%27%29%3D%5Cmathrm%7BE%7D%5Cbig%5B%5Cmathrm%7BGain%7D_%7Bd%27%7D-%5Cmathrm%7BGain%7D_%7Bd%7D%5Cmid+x%2C%5C%2C%5Cboldsymbol%7B%5Cphi%7D_%7Bd%7D%5Cbig%5D-c_t%5C%2C%5CDelta+t%28d%2Cd%27%29-c_c%5C%2C%5Cmathrm%7BCost%7D%28d%27%29&bg=ffffff&fg=000&s=0&c=20201002)
Policy: jump if 

Part 4 — Evaluation plan (what we’ll test if we proceed)
- Datasets: representative public text/code retrieval sets + a synthetic meet-again benchmark.
- Metrics: AUQC (Area-Under Quality-vs-Compute), Budget frontier (p50/p90/p95 quality vs. latency/compute), Zoom-AUC, Thrash@τ (hysteresis reversals), Neighbor-Stability (Kendall-τ across depths), Hubness skew, Recall@K per rung, Jump@K, dims-per-jump, braid/meet-again indices, DDP AUC, cost (re-ranks/tokens, p95 latency).
- Baselines: 1024-only retriever; early-exit escalator (no lift); cross-encoder re-rank; dimensional ensembling; ours (proposed) without vs. with fold-aware jumps.
- Ablations: remove each DDP loss; remove lift; remove fold features one-by-one; ladder/anchor variants; basis swaps with versioning.
- Stats: bootstrap CIs, paired permutation tests, effect sizes.
Ops & CI (regression guards)
- AUQC/Budget frontier: track movement of the frontier release-to-release.
- Neighbor-Stability: mean ± SE of Kendall-τ across depths.
- Zoom-AUC and Thrash@τ to catch oscillation.
- Conformal coverage: empirical coverage vs. target (1−α).
- Index telemetry: HNSW hops, PQ recall@K, GPU util.
Acceptance tests (go/no-go)
- Compute ↓, Quality =/↑: AUQC ↑ or p95 latency ↓ ≥10% at matched Hit@1.
- Stability: Kendall-τ SE ↓ ≥10% (fewer cross-depth neighbor flips).
- Abstention: conformal coverage within ±1.5% of target (1−α).
- Retrieval: final-rung recall@10 ≥0.98× brute-force on a 1M shard; ≥5× speedup with HNSW+slice-PQ.
Part 5 — Potential benefits (if validated)
Reduced compute by avoiding brute-force high-d on everything.
Long-tail improvements (polysemy, rare relations) via early fold-aware jumps.
Ops clarity: explicit budgets, thresholds, versioned bases for audits.
Part 6 — Limitations & risks (up front)
- Fold cues may be noisy → over-jump; needs budget/entropy priors.
- Sensitivity to basis versioning and domain shift in fold statistics.
- As with any retrieval improvement, consider policy/safety filters.
Part 7 — Learn more / follow along
Working draft, LaTeX, configs, and notes will live in the OSF project:
OSF: https://osf.io/85z3u
We’ll update that page with code and evaluation artifacts if we move to experiments.